

در این مطلب سوالات و پاسخهای متداول مصاحبه برنامه نویس بکند در سه سطح مبتدی، متوسط و پیشرفته را بررسی میکنیم.
فهرست محتوا
- سطح مبتدی
- ۱. API Endpoint چیست؟
- ۲. تفاوت پایگاه دادههای SQL و NoSQL چیست؟
- ۳. RESTful API چیست و اصول کلیدی آن کدامند؟
- ۴. چرخه معمول درخواست/پاسخ HTTP چگونه است؟
- ۵. مدیریت آپلود فایل در وباپلیکیشن چگونه انجام میشود؟
- ۶. چه تستهایی برای یک API Endpoint جدید لازم است؟
- ۷. مدیریت نشست (Session Management) در وب چگونه انجام میشود؟
- ۸. نسخهبندی API چگونه انجام میشود؟
- ۹. محافظت در برابر SQL Injection
- ۱۰. Stateless بودن HTTP و تأثیر آن بر بکاند
- ۱۱. Containerization چیست و چه مزیتی دارد؟
- ۱۲. اقدامات امنیتی برای API جدید
- ۱۳. مقیاسبندی بکاند هنگام افزایش ترافیک
- ۱۴. ابزارها و تکنیکهای Debug بکاند
- ۱۵. نگهداری و قابل فهم بودن کد بکاند
- سطح متوسط
- ۱. پیادهسازی جستجوی تماممتن در پایگاه داده چگونه است؟
- ۲. پردازش دستهای (Batch Processing) در برنامههای دادهمحور
- ۳. استفاده و مزایای Message Queue در سیستم توزیعشده
- ۴. مدیریت اتصالات پایگاه داده در شرایط بار زیاد
- ۵. راهاندازی CI/CD برای سرویسهای بکاند
- ۶. استراتژی کش توزیعشده (Distributed Caching) برای برنامه با دسترسپذیری بالا
- ۷. مدیریت وظایف پسزمینه (Background Tasks)
- ۸. رمزگذاری و رمزگشایی دادهها در اپلیکیشنهای حفاظتشده از حریم خصوصی
- ۹. Webhooks و پیادهسازی آنها
- ۱۱. مدیریت فرآیندهای طولانی در وباپلیکیشن
- ۱۲. Rate Limiting برای حفاظت از API
- ۱۳. نظارت و مانیتورینگ عملکرد اپلیکیشنهای بکاند
- ۱۴. میکروسرویسها و تجزیه Monolith
- ۱۵. مدیریت وابستگیهای API در بکاند
- ۱۶. مفهوم Eventual Consistency در سیستمهای توزیعشده
- ۱۷. Reverse Proxy و کاربرد آن در بکاند
- ۱۸. مدیریت Session در محیط Load-Balanced
- سطح پیشرفته
- ۱. تکثیر پایگاه داده (Database Replication) و استفاده آن برای تحمل خطا
- ۲. استراتژی استقرار Blue-Green در سرویسهای بکاند
- ۳. مدلهای همسانی (Consistency Models) در پایگاه دادههای توزیعشده – قضیه CAP
- ۴. مدیریت Migration اسکیمای پایگاه داده در محیط Continuous Delivery
- ۵. مدیریت Idempotency در طراحی REST API
- ۶. پیادهسازی Single Sign-On (SSO)
- ۷. توسعه سیستم بکاند برای جریان دادههای IoT
- ۸. همگامسازی دادهها در زمان واقعی بین دستگاهها
- ۹. مزایا و معایب معماری میکروسرویسها
- ۱۰. تست بار (Load Testing) API
- ۱۱. استراتژی Server-Side Cache Eviction
- ۱۲. Correlation IDs برای ردیابی درخواستها
- ۱۳. تفاوت Locking خوشبینانه و بدبینانه در تراکنشهای پایگاه داده
- ۱۴. جلوگیری از Deadlock در تراکنشهای پایگاه داده
- ۱۵. امنیت ارتباط بین سرویسها در میکروسرویسها
- ۱۶. پیشگیری و شناسایی دادههای نادرست در سیستمهای بزرگ
- ۱۷. ایجاد ذخیرهسازی داده و با دسترسپذیری بالا
سطح مبتدی
۱. API Endpoint چیست؟
API Endpoint یک URL مشخص است که به عنوان نقطه ورود به یک سرویس یا عملکرد خاص در یک سرویس عمل میکند.
از طریق این نقطه، برنامههای کلاینت میتوانند درخواستهایی به سرور ارسال کرده و پاسخ دریافت کنند. این درخواستها گاهی شامل دادههایی در قالب payload هستند.
معمولاً هر Endpoint با یک ویژگی یا عملکرد مشخص در سرور مرتبط است و به آن سرویس اجازه میدهد تا به شکل منظم با کلاینتها تعامل داشته باشد.
۲. تفاوت پایگاه دادههای SQL و NoSQL چیست؟
- SQL یا پایگاه دادههای رابطهای: ساختار دادهها از قبل تعریف شده است. هر جدول یا رکورد باید طبق یک الگوی مشخص (نام و فیلدها) ایجاد شود.
- NoSQL: هیچ ساختار از پیش تعیینشدهای وجود ندارد. دادهها معمولاً در مجموعههایی ذخیره میشوند که لازم نیست همگی ساختار یکسان داشته باشند، حتی اگر به لحاظ مفهومی مشابه باشند.
۳. RESTful API چیست و اصول کلیدی آن کدامند؟
یک API زمانی RESTful محسوب میشود که اصول REST را رعایت کند:
- معماری کلاینت-سرور: جداسازی وظایف کلاینت و سرور برای استقلال بیشتر.
- رابط یکنواخت (Uniform Interface):
- هر منبع از طریق URI یکتا قابل شناسایی باشد.
- منابع بتوانند از طریق نمای خود (Representation) تغییر کنند.
- پیامها خودتوضیح دهنده باشند و اطلاعات کافی برای پردازش را فراهم کنند.
- کلاینت بتواند با استفاده از پاسخ سرور اقدامات موجود روی منابع را کشف کند (HATEOAS).
- Stateless بودن: هر درخواست باید شامل تمام اطلاعات لازم برای پردازش باشد.
- سیستم لایهای: ارتباط بین کلاینت و سرور میتواند از طریق واسطهها برقرار شود بدون اینکه عملکرد مختل شود.
- قابلیت کش کردن منابع: کش شدن دادهها توسط کلاینت یا سرور.
- اختیاری – Code on Demand: سرور میتواند کدی برای اجرا به کلاینت ارسال کند.
۴. چرخه معمول درخواست/پاسخ HTTP چگونه است؟
HTTP یک پروتکل ساختیافته است که مراحل مشخصی دارد:
- باز کردن اتصال: کلاینت یک اتصال TCP به سرور باز میکند (پورت ۸۰ برای HTTP و ۴۴۳ برای HTTPS).
- ارسال درخواست: درخواست شامل متد HTTP (GET, POST, PUT, DELETE و …)، URI، نسخه HTTP، هدرها و در صورت نیاز بدنه (Body) است.
- پردازش درخواست توسط سرور: سرور درخواست را پردازش کرده و پاسخ آماده میکند.
- ارسال پاسخ: پاسخ شامل نسخه HTTP، کد وضعیت، هدرها و بدنه (اختیاری) است.
- بستن اتصال: اتصال معمولاً بسته میشود، اما در نسخههای جدیدتر HTTP امکان باز نگه داشتن آن وجود دارد.
۵. مدیریت آپلود فایل در وباپلیکیشن چگونه انجام میشود؟
توسعهدهندگان بکاند هنگام مدیریت فایلهای آپلود شده باید نکات زیر را رعایت کنند:
- اعتبارسنجی سمت سرور: بررسی اندازه و نوع فایل مطابق استانداردها.
- استفاده از کانال امن: آپلود باید از طریق HTTPS انجام شود.
- جلوگیری از تداخل نام فایلها: نام فایلها را به شکل یکتا ذخیره کنید تا از خطاهای برنامه جلوگیری شود.
- نگهداری متادیتا: اطلاعات فایلها را در دیتابیس ذخیره کنید و نام اصلی فایلها را نیز ثبت کنید.
۶. چه تستهایی برای یک API Endpoint جدید لازم است؟
- Unit Test: تست منطق اصلی برنامه بدون وابستگی به سرویسهای خارجی.
- Integration Test: بررسی عملکرد کامل Endpoint و تعامل آن با سرویسهای خارجی مانند پایگاه داده یا API دیگر.
- Load/Performance Test: بررسی عملکرد Endpoint تحت فشار و ترافیک بالا قبل از انتشار.
۷. مدیریت نشست (Session Management) در وب چگونه انجام میشود؟
- ایجاد نشست: هنگام اولین تعامل کاربر (معمولاً ورود)، یک شناسه نشست (Session ID) ایجاد میشود.
- ذخیره اطلاعات نشست: دادههای نشست در حافظه یا دیتابیس (مثل Redis) ذخیره میشوند.
- ارسال شناسه به کلاینت: معمولاً از طریق کوکی به کلاینت فرستاده میشود.
- ارسال شناسه توسط کلاینت: کلاینت در هر درخواست، شناسه نشست را به سرور میفرستد.
- دسترسی به دادههای نشست در سرور: سرور با استفاده از Session ID دادهها را بازیابی میکند.
- پایان نشست: پس از مدتی یا با اقدام کاربر، نشست خاتمه یافته و دادهها حذف میشوند.
۸. نسخهبندی API چگونه انجام میشود؟
- قرار دادن نسخه در URL:
/v1/your-api/usersیا/your-api/users?v=1 - استفاده از هدر سفارشی: هدرهایی مانند
api-versionکه نسخه مورد نظر را مشخص میکنند.
۹. محافظت در برابر SQL Injection
- Prepared Statements: استفاده از کوئریهایی با پارامتر برای جلوگیری از تزریق.
- استفاده از ORM: فریمورکهایی که SQL ایمن تولید میکنند.
- Escaping Data: حذف کردن کاراکترهای ویژه به صورت دستی برای جلوگیری از آسیبپذیریها.
۱۰. Stateless بودن HTTP و تأثیر آن بر بکاند
HTTP پروتکلی بدون وضعیت است؛ یعنی هر درخواست مستقل از درخواستهای قبلی است. بنابراین، بکاند در صورت نیاز باید مدیریت حالت (State Management) خود را پیادهسازی کند.
۱۱. Containerization چیست و چه مزیتی دارد؟
Containerization یک روش مجازیسازی سبک است که برنامهها و وابستگیهای آنها را پکیج میکند تا در محیطهای مختلف یکسان اجرا شوند.
مزایا برای بکاند: جداسازی، قابلیت حمل، سادهسازی استقرار و کاهش تداخل نسخهها و پیکربندیها.
۱۲. اقدامات امنیتی برای API جدید
- افزودن روش احراز هویت مانند OAuth، JWT، Session-based و غیره.
- استفاده از HTTPS برای رمزنگاری دادهها.
- تنظیم سیاستهای CORS قوی برای جلوگیری از درخواستهای ناخواسته.
- پیادهسازی منطق مجوزدهی دقیق تا کاربران فقط به منابع مجاز دسترسی داشته باشند.
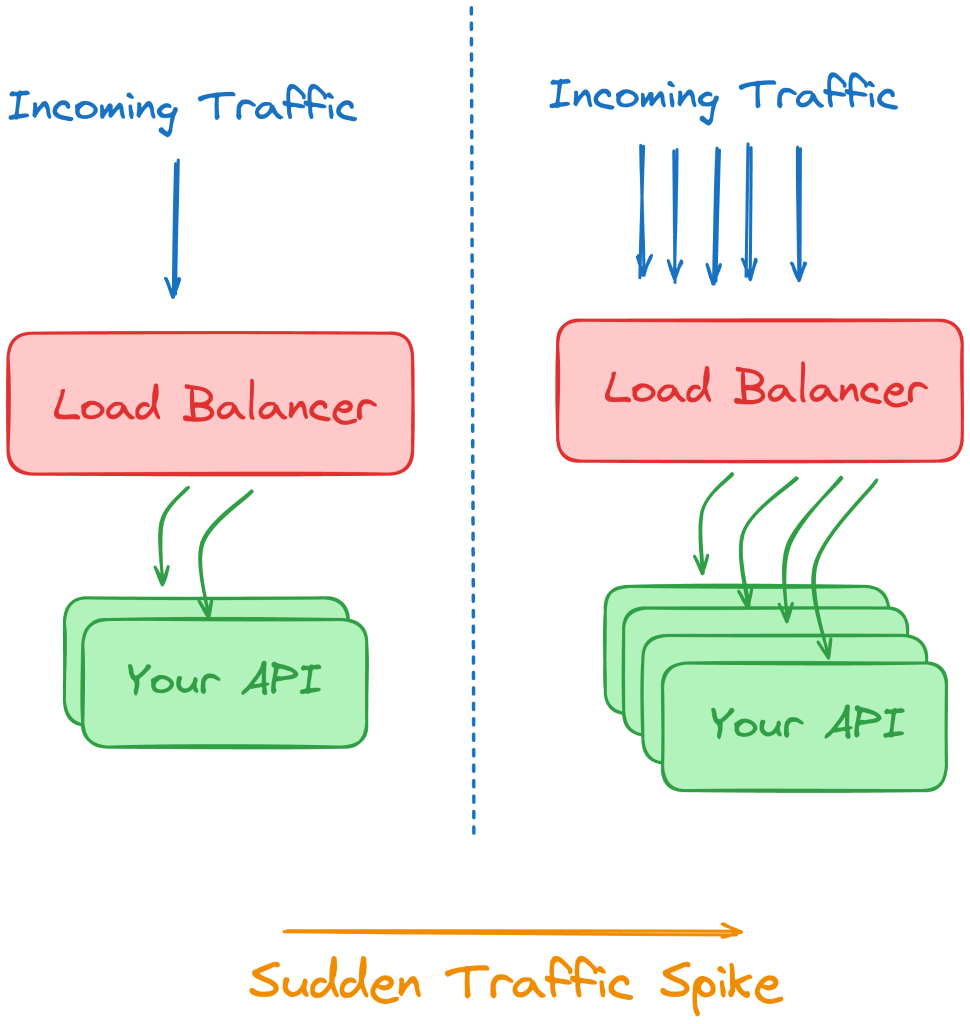
۱۳. مقیاسبندی بکاند هنگام افزایش ترافیک
روش معمول: استفاده از چندین Instance از برنامه پشت یک Load Balancer و افزودن جدید هنگام افزایش ترافیک. این روش مقیاسپذیری افقی (Horizontal Scaling) نام دارد و برای برنامههای بدون وضعیت (Stateless) بهترین عملکرد را دارد.
۱۴. ابزارها و تکنیکهای Debug بکاند
- محلی (Local): IDEهایی مانند IntelliJ و Eclipse با قابلیت Debug داخلی.
- روی سرور: استفاده از Logging یا ابزارهای حرفهای مانند JProfiler و NewRelic.
۱۵. نگهداری و قابل فهم بودن کد بکاند
- ماژولار بودن
- استانداردهای نامگذاری
- اضافه کردن کامنتها و مستندات
- Refactor منظم برای کاهش بدهی فنی
- یکسانسازی پیامهای خطا
- نوشتن Unit Test برای همه بخشهای کد
سطح متوسط
۱. پیادهسازی جستجوی تماممتن در پایگاه داده چگونه است؟
برای پیادهسازی جستجوی تماممتن میتوان از امکانات داخلی پایگاههای داده مانند MySQL، PostgreSQL یا ElasticSearch استفاده کرد.
اما اگر بخواهید خودتان آن را پیاده کنید:
- پیشپردازش دادهها: متنها را با روشهایی مثل Tokenization، Stemming و حذف Stop Words نرمال کنید.
- ایجاد ایندکس معکوس (Inverted Index): هر کلمه منحصر به فرد را به رکوردهایی که شامل آن است، مرتبط کنید.
- ایجاد رابط جستجو: ورودی کاربر را مشابه دادهها نرمال کنید.
- جستجو در پایگاه داده: برای هر کلمه جستجو انجام دهید.
- مرتبسازی نتایج: بر اساس فرکانس کلمات و سایر معیارها، نمرهدهی و مرتبسازی کنید.
۲. پردازش دستهای (Batch Processing) در برنامههای دادهمحور
بهترین گزینه استفاده از فریمورکهای پردازش دستهای مانند Hadoop یا Spark است که توان پردازش موازی حجم بالای دادهها را دارند.
۳. استفاده و مزایای Message Queue در سیستم توزیعشده
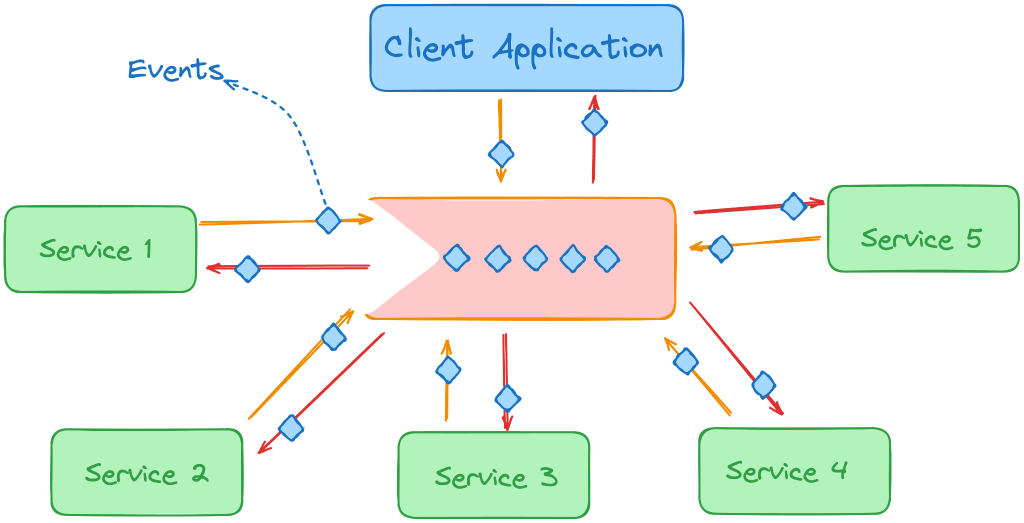
Message Queue هسته معماری واکنشی (Reactive Architecture) است. هر سرویس میتواند رویدادها را در صف شنیده و واکنش نشان دهد، بدون نیاز به پرسوجوی مداوم از سایر سرویسها.
۴. مدیریت اتصالات پایگاه داده در شرایط بار زیاد
- استفاده از Connection Pool برای کاهش زمان ایجاد اتصال جدید.
- Load Balancing بین چند پایگاه داده برای توزیع بار.
- بهینهسازی کوئریها برای کاهش زمان استفاده از هر اتصال و بهبود بهرهوری منابع.
۵. راهاندازی CI/CD برای سرویسهای بکاند
- استفاده از کنترل نسخه (مثلاً Git) برای شروع فرآیند.
- انتخاب پلتفرم مناسب CI/CD مانند GitHub Actions، GitLab CI/CD یا CircleCI.
- اجرای Unit Test خودکار در خطوط ساخت (Pipeline).
- استقرار خودکار تنها در صورت موفقیت تستها.
- استفاده از مخزن Artifacts مانند JFrog Artifactory یا Nexus Repository.
- تعریف استراتژی Rollback در صورت بروز خطا.
۶. استراتژی کش توزیعشده (Distributed Caching) برای برنامه با دسترسپذیری بالا
- ایجاد خوشهای از سرورها به عنوان کش توزیعشده و استفاده از Sharding برای توزیع دادهها.
- پیادهسازی Cache Replication برای افزونگی دادهها و تحمل خطا.
- اجرای مکانیزم Cache Invalidation برای جلوگیری از استفاده از دادههای قدیمی.
۷. مدیریت وظایف پسزمینه (Background Tasks)
بسته به تکنولوژی شما، گزینهها شامل:
- Task Queues مانند RabbitMQ یا Amazon SQS با ورکرهای (Workers) پسزمینه.
- فریمورکهای Background Job مانند Celery (Python) یا Sidekiq (Ruby).
- استفاده از Cron Jobs.
- استفاده از Threads یا Workers در همان اپلیکیشن در صورت پشتیبانی زبان برنامهنویسی.
۸. رمزگذاری و رمزگشایی دادهها در اپلیکیشنهای حفاظتشده از حریم خصوصی
- Data at Rest (دادههای ذخیرهشده): استفاده از الگوریتمهای قدرتمند AES، RSA یا ECC و نگهداری کلیدها در ابزارهای مدیریت کلید (KMS).
- Data in Transit (دادههای در حال انتقال): ارتباط از طریق کانالهای امن و رمزنگاریشده مثل HTTPS.
۹. Webhooks و پیادهسازی آنها
Webhooks یک Callback HTTP تعریفشده توسط کاربر است که با رخداد خاصی فعال میشود:
- تعریف رویدادها: مشخص کنید چه رویدادهایی پیام را به Webhook ارسال میکنند و چه Payload دارند.
- ایجاد Endpoint: Endpoint HTTP متناسب با نوع درخواست (POST یا GET).
- امنیت: اطمینان از امن بودن Endpoint در برابر سوءاستفاده.
۱۰. رعایت GDPR در سیستمهای بکاند
- تنها دادههای ضروری را جمعآوری کنید.
- دادهها را در حال انتقال و ذخیرهسازی امن نگه دارید و ممیزیهای امنیتی انجام دهید.
- به کاربران امکان مشاهده، ویرایش یا حذف دادههای خود را بدهید.
۱۱. مدیریت فرآیندهای طولانی در وباپلیکیشن
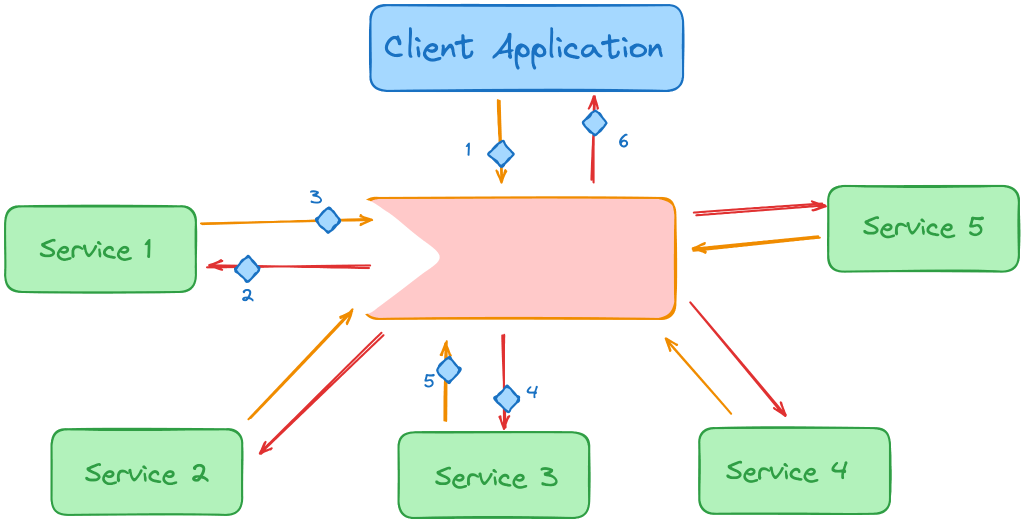
بهترین راه، استفاده از Reactive Architecture است:
- درخواست کاربر به پیام در صف تبدیل میشود.
- فرآیند طولانی وقتی آماده شد، آن پیام را پردازش میکند.
- کلاینت پاسخ فوری دریافت میکند که فرآیند در حال پردازش است.
۱۲. Rate Limiting برای حفاظت از API
- تعریف محدودیتها: تعداد درخواستها در دقیقه، ثانیه یا روز.
- انتخاب الگوریتم محدودسازی: Fixed Window, Sliding Log, Token Bucket یا Leaky Bucket.
- ذخیرهشدن شمارندهها: از دیتاستهای سریع مانند Redis.
- پاسخ استاندارد پس از رسیدن به حد: کد 429 (Too Many Requests).
۱۳. نظارت و مانیتورینگ عملکرد اپلیکیشنهای بکاند
استفاده از APM (Application Performance Management) مانند New Relic، AppDynamics یا Dynatrace برای شناسایی گلوگاهها و بررسی عملکرد.
۱۴. میکروسرویسها و تجزیه Monolith
- میکروسرویسها مجموعهای از سرویسهای مستقل حول نیازهای کسبوکار هستند.
- مراحل تجزیه Monolith:
- شناسایی مرزهای منطقی Monolith
- تعریف سرویسها و جدا کردن دادهها
- Refactor تدریجی و استخراج منطق به میکروسرویسهای مستقل
۱۵. مدیریت وابستگیهای API در بکاند
- استفاده از API Versioning برای اطمینان از استفاده از نسخه صحیح API.
- امکان استفاده از نسخههای متفاوت یک API توسط سیستمهای مختلف بدون ایجاد مشکل.
۱۶. مفهوم Eventual Consistency در سیستمهای توزیعشده
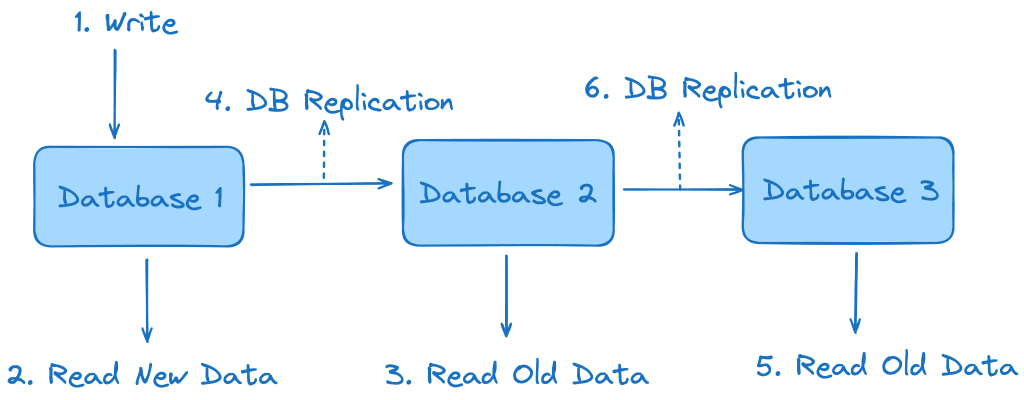
- Eventual Consistency تضمین میکند که دادهها در طول زمان در تمام سرورها همسان میشوند، نه فوراً.
- نیاز به همگامسازی دادهها و حل تعارضات احتمالی در سیستمهای توزیعشده.
۱۷. Reverse Proxy و کاربرد آن در بکاند
Reverse Proxy سروری است که ترافیک را بین چند سرور دیگر هدایت میکند و میتواند:
- Load Balancing بین سرورها
- ایجاد لایه امنیتی اضافی و محافظت در برابر حملات (مانند DDoS)
- کش کردن محتوا برای کاهش بار سرورها
- امکان تغییر سرویسهای بکاند بدون تأثیر روی URLهای عمومی
۱۸. مدیریت Session در محیط Load-Balanced
- Sticky Sessions: ارسال درخواستهای یک کلاینت به همان سرور. معایب: توزیع نامتعادل ترافیک.
- Centralized Session Store: نگهداری دادههای نشست در یک دیتاست مرکزی مشترک بین تمام سرورها. مزایا: توزیع متعادل، نیازمند منطق اضافی.
سطح پیشرفته
۱. تکثیر پایگاه داده (Database Replication) و استفاده آن برای تحمل خطا
تکثیر پایگاه داده به معنای کپی شدن دادهها در چند نمونه از همان پایگاه داده است. معمولاً یک پایگاه داده به عنوان Master عمل میکند و سایر پایگاهها به عنوان Slave بهروزرسانیهای داده را دریافت میکنند.
مزایای این روش در تحمل خطا (Fault Tolerance) عبارتاند از:
- در صورت بروز مشکل در Master، یکی از Slaveها میتواند به جای آن فعال شود بدون اینکه دادهای از دست برود.
- Slaveها میتوانند به صورت فقط خواندنی استفاده شوند، که تعداد درخواستهای خواندنی افزایش یافته و عملکرد پایگاه داده کاهش نمییابد.
۲. استراتژی استقرار Blue-Green در سرویسهای بکاند
استراتژی Blue-Green شامل داشتن دو محیط تولیدی مشابه است:
- یکی از آنها در حال سرویسدهی به ترافیک واقعی است.
- دیگری آماده بهروزرسانی نسخه جدید یا به عنوان پشتیبان قرار دارد.
۳. مدلهای همسانی (Consistency Models) در پایگاه دادههای توزیعشده – قضیه CAP
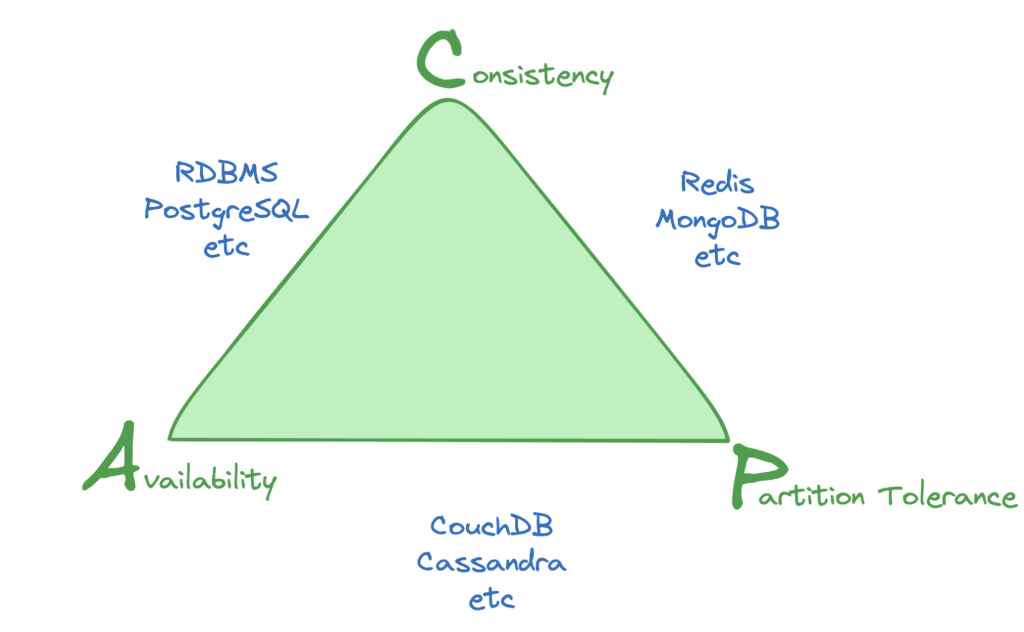
۴. مدیریت Migration اسکیمای پایگاه داده در محیط Continuous Delivery
- پیگیری نسخهها: فایلهای Migration اسکیمای خود را همراه با کد در کنترل نسخه نگه دارید.
- ابزارهای خودکار: از ابزارهایی مانند Flyway یا Liquibase برای استانداردسازی و سادهسازی مهاجرتها استفاده کنید.
۵. مدیریت Idempotency در طراحی REST API
- از HTTP Verbs استفاده کنید: عملیات idempotent شامل GET، PUT و DELETE هستند.
- یا با منطق کلید-محور، از اجرای مجدد یک عملیات جلوگیری کنید، اگر کلید ارائهشده توسط کلاینت ثابت باشد.
۶. پیادهسازی Single Sign-On (SSO)
مراحل کلی:
- انتخاب یک Identity Provider مانند Okta یا Keycloak.
- هر اپلیکیشن با پروتکل SSO استاندارد (SAML، OpenID و …) به Identity Provider متصل میشود.
- هنگام اولین دسترسی کاربر، اپلیکیشن با IdP ارتباط برقرار کرده و توکن دسترسی دریافت میکند.
- درخواستهای بعدی با اعتبارسنجی توکن از طریق IdP انجام میشود.
۷. توسعه سیستم بکاند برای جریان دادههای IoT
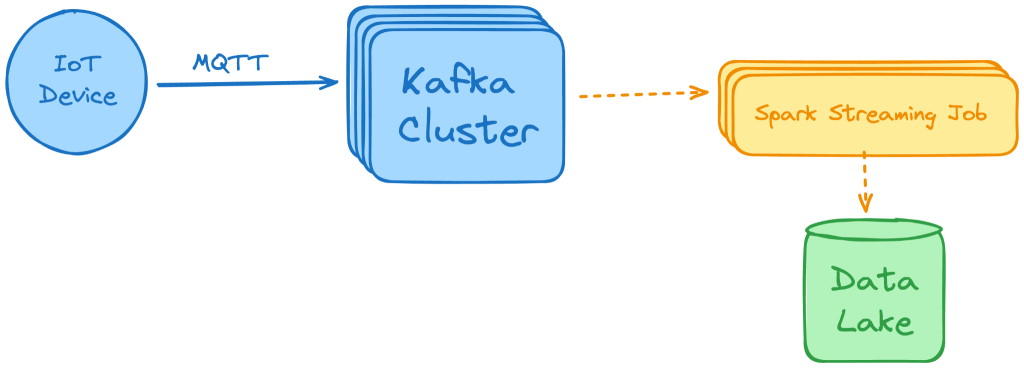
- استفاده از سرویسهای مقیاسپذیر جمعآوری داده مانند Kafka یا AWS Kinesis با پروتکلهای IoT استاندارد (MQTT یا CoAP).
- پردازش دادهها با موتورهای پردازش لحظهای مانند Apache Flink یا Spark Streaming.
- ذخیرهسازی دادهها در یک Data Lake مقیاسپذیر، ترجیحاً سازگار با دادههای Time-Series مانند InfluxDB.
۸. همگامسازی دادهها در زمان واقعی بین دستگاهها
- استفاده از کانالهای دوطرفه مبتنی بر Socket یا مدل Pub/Sub (مثلاً Redis یا Kafka) برای توزیع دادهها.
- حل تعارض دادهها با الگوریتمهایی مانند Operational Transformation (OT) یا CRDTs.
۹. مزایا و معایب معماری میکروسرویسها
مزایا:
- مقیاسپذیری مستقل هر سرویس
- انعطافپذیری فناوری برای نیازهای هر سرویس
- استقرار سریعتر و بهروزرسانیهای مجزا
معایب:
- پیچیدگی بالاتر معماری
- دشواری در دیباگینگ و ردیابی درخواستها
- سربار ارتباط بین سرویسها
۱۰. تست بار (Load Testing) API
- اهداف تست و محیطی شبیه به تولید را مشخص کنید.
- تستها را با ابزارهای انتخابی (JMeter، LoadRunner و …) طراحی و اجرا کنید.
- بار را به تدریج افزایش دهید و عملکرد سیستم را بررسی کنید.
- API را بهینهسازی کرده و تستها را دوباره انجام دهید تا به نتیجه مطلوب برسید.
۱۱. استراتژی Server-Side Cache Eviction
- تعریف حداکثر اندازه کش و زمان فعال شدن Eviction
- مکانیزم Cache Invalidation
- سیاستهای Eviction: LRU، LFU، FIFO، Random، TTL
۱۲. Correlation IDs برای ردیابی درخواستها
- شناسههای یکتا که به درخواستها اضافه میشوند تا مسیر آنها در سیستم توزیعشده ردیابی شود.
- کمک به دیباگ و شناسایی مشکلات عملکردی یا خطاها.
۱۳. تفاوت Locking خوشبینانه و بدبینانه در تراکنشهای پایگاه داده
Optimistic Locking:
- فرض بر نادر بودن تعارض
- اجازه دسترسی همزمان
- بررسی تعارض قبل از Commit
- مناسب سناریوهای High-Read و Low-Write
Pessimistic Locking:
- فرض بر رایج بودن تعارض
- قفل کردن دادهها و جلوگیری از دسترسی همزمان
- نگه داشتن قفل تا پایان تراکنش
- مناسب سناریوهای High-Write یا داده حساس
۱۴. جلوگیری از Deadlock در تراکنشهای پایگاه داده
- Lock Ordering: گرفتن قفلها به ترتیب ثابت
- Timeout برای تراکنشهای طولانی
- استفاده از Optimistic Concurrency برای کاهش مدت نگهداری قفلها
۱۵. امنیت ارتباط بین سرویسها در میکروسرویسها
- استفاده از کانالهای رمزنگاریشده (TLS)
- استفاده از API Gateway برای مدیریت و احراز هویت ترافیک
- اعمال Authentication و Authorization برای پیامهای بین سرویسها
۱۶. پیشگیری و شناسایی دادههای نادرست در سیستمهای بزرگ
- تعریف و اجرای Validation Rules و محدودیتهای اسکیمایی
- Data Versioning برای بازگردانی سریع دادهها
- پیادهسازی Data Quality Practice برای اعتبارسنجی دادهها
۱۷. ایجاد ذخیرهسازی داده و با دسترسپذیری بالا
- محیطهای Multi-Zone در Cloud (AWS، Azure، GCP)
- Replication دادهها بین سرورها و مناطق مختلف
- Load Balancing برای توزیع بهینه ترافیک
- سیاستهای Data Governance و رعایت قوانین محلی (مانند GDPR)
