OpenAI در حال شفافتر کردن جایگاه ChatGPT در جریانهای کاری واقعی توسعه نرمافزار است و مدل GPT-5.2 تاکنون روشنترین نشانه این تغییر رویکرد به شمار میرود. این مدل جدید در شرایطی معرفی شده که تیمهای فنی بهدنبال پاسخ به یک پرسش کلیدی هستند: کدام سیستمهای هوش مصنوعی میتوانند کدنویسی، دیباگ و انجام وظایف چندمرحلهای را با اطمینان در محیطهای عملیاتی (Production) انجام دهند؟
عرضه GPT-5.2 پس از اعلام یک «وضعیت اضطراری داخلی» یا همان Code Red در OpenAI صورت گرفته است؛ تصمیمی که باعث شد منابع انسانی و محاسباتی شرکت بهجای توسعه قابلیتهای جدید، روی بهبود ChatGPT متمرکز شوند.
فیدجی سیمو، مدیرعامل بخش اپلیکیشنهای OpenAI، در گفتوگو با خبرنگاران اعلام کرد:
«با اعلام Code Red میخواستیم بهروشنی نشان دهیم که تمرکز شرکت روی یک حوزه مشخص است. این کار به ما کمک میکند اولویتها را دقیقتر تعریف کنیم. منابع اختصاصیافته به ChatGPT بهطور محسوسی افزایش یافته است.»
سیمو تأکید میکند که GPT-5.2 ماهها در دست توسعه بوده و محصولی شتابزده در واکنش به Code Red نیست. با این حال، عرضه آن کمتر از یک ماه پس از GPT-5.1 نشان میدهد که چرخه بهروزرسانیها سریعتر شده؛ موضوعی که به تشدید رقابت در حوزه ابزارهای توسعهدهندگان برمیگردد.
رقابت فشرده در بازار ابزارهای هوش مصنوعی برای توسعهدهندگان
از زمان معرفی ChatGPT در سال ۲۰۲۲، OpenAI انتخاب پیشفرض بسیاری از توسعهدهندگانی بود که به سراغ کدنویسی با کمک هوش مصنوعی میرفتند. اما این جایگاه حالا با چالشهای جدی مواجه شده است.
مدل Gemini 3 گوگل توانسته توجه بخشی از جامعه توسعهدهندگان را جلب کند و در سوی دیگر، مدلهای Claude از شرکت Anthropic بهویژه در محیطهای سازمانی محبوبیت بالایی پیدا کردهاند. برخی برآوردهای صنعتی حتی نشان میدهد Claude در بخشهایی از بازار نرمافزارهای سازمانی از OpenAI پیشی گرفته است.
در چنین فضایی، تمرکز GPT-5.2 بهوضوح روی توسعه نرمافزار و استدلال پیچیده قرار دارد.
مدلهای چندسطحی برای نیازهای متفاوت
OpenAI، GPT-5.2 را در قالب چند سطح مختلف عرضه کرده است:
Instant: برای پاسخهای سریع و پرسشهای ساده
Thinking: مناسب وظایف پیچیدهتر مانند کدنویسی، ریاضیات و برنامهریزی
Pro: برای کاربرانی که در مسائل دشوار یا مبهم به بالاترین دقت نیاز دارند
به گفته OpenAI، GPT-5.2 توانمندترین مدل این شرکت برای کارهای حرفهای روزمره محسوب میشود.
در بنچمارک داخلی OpenAI با نام GDPval (که عملکرد مدلهای هوش مصنوعی را در ۴۴ شغل مختلف با متخصصان انسانی مقایسه میکند) نسخه Thinking از GPT-5.2 بالاترین امتیاز ثبتشده در تاریخ OpenAI را به دست آورده است. طبق اعلام شرکت، این مدل در بیش از ۷۰ درصد وظایف به سطحی برابر یا بالاتر از متخصصان انسانی رسیده است؛ عملکردی بهتر از مدلهای قبلی OpenAI و حتی برخی مدلهای جدید گوگل و Anthropic.
عملکرد قویتر در بنچمارکهای کدنویسی
برای توسعهدهندگان، نتایج بنچمارکهای کدنویسی اهمیت بیشتری دارد. در آزمون SWE-Bench Pro (که وظایف واقعی مهندسی نرمافزار را شبیهسازی میکند) GPT-5.2 امتیازی بالاتر از GPT-5.1 و مدل Gemini 3 Pro گوگل کسب کرده است.
OpenAI همچنین اعلام کرده که این مدل در کار با ابزارهای نرمافزاری خارجی و اجرای جریانهای کاری چندمرحلهای عملکرد بهتری دارد؛ قابلیتی که برای سیستمهای مبتنی بر «ایجنت» (Agent-style systems) بهسرعت در حال تبدیل شدن به یک استاندارد است.
این ادعاها تا حدی بر اساس بازخورد مشتریان آلفا مطرح شده است؛ شرکتهایی که چند هفته پیش از عرضه رسمی به GPT-5.2 دسترسی داشتند. از جمله این کاربران اولیه میتوان به Harvey، Notion، Box، Shopify و Zoom اشاره کرد.
کاهش خطاهای ساختگی (Hallucination)
دقت پاسخها یکی از محورهای اصلی توسعه GPT-5.2 بوده است. مکس شوارتزر، مسئول مرحله پسآموزش (Post-training) در OpenAI، میگوید این مدل کاهش محسوسی در خطاهای ساختگی داشته است.
طبق اعلام OpenAI، در بنچمارکهای مبتنی بر پاسخهای factual، نسخه Thinking از GPT-5.2 نسبت به GPT-5.1 ۳۸ درصد خطای Hallucination کمتری تولید کرده است؛ شاخصی حیاتی برای تیمهایی که مدلها را مستقیماً در محیطهای عملیاتی استفاده میکنند.
چالشهایی فراتر از بنچمارکها
با وجود بهبودهای فنی، تجربه کاربری همچنان عامل تعیینکنندهای است که بنچمارکها همیشه آن را نشان نمیدهند. زمانی که GPT-5 در ابتدای سال معرفی شد، برخی کاربران از پاسخهایی انتقاد کردند که بیش از حد خشک و غیرشخصی به نظر میرسید. OpenAI بعدها با انتشار یک بهروزرسانی، لحن مدل را اصلاح کرد؛ اقدامی که نشان میدهد پذیرش توسعهدهندگان تنها به قدرت فنی وابسته نیست.
در کنار این موضوع، OpenAI با افزایش استفاده روزمره از ChatGPT، زیر ذرهبین بیشتری در زمینه تعاملات حساس کاربران قرار گرفته است. این شرکت در گزارشی اعلام کرده بیش از یک میلیون نفر در هفته درباره خودکشی با ChatGPT گفتوگو میکنند و تأکید دارد که تقویت سازوکارهای ایمنی بخشی از تلاشهای مستمر حاکمیتی آن است.
Claude یا GPT؟ انتخابی بر اساس «تناسب»، نه صرفاً قدرت
با تشدید رقابت، توسعهدهندگان بیش از گذشته در حال سنجیدن مزایا و معایب GPT و Claude هستند:
Claude: مناسب استدلال با کانتکست طولانی و وظایف ساختاریافته کدنویسی
در نهایت، برای بسیاری از تیمها انتخاب مدل دیگر صرفاً به «قویتر بودن» خلاصه نمیشود، بلکه به میزان تطابق با نیازهای پروژه بستگی دارد. با کوتاهتر شدن چرخه انتشار مدلها و بهبود مستمر بنچمارکها، احتمالاً بسیاری از تیمها بهجای وابستگی به یک ارائهدهنده، چند مدل مختلف را بهصورت همزمان آزمایش و استفاده خواهند کرد.
دو سال و نیم پیش انسانیت شاهد آغاز بزرگترین دستاورد خود بود. یا شاید بهتر باشد بگویم: با آن آشنا شدیم: ChatGPT. از زمان عرضه آن در نوامبر ۲۰۲۲، اتفاقات زیادی رخ داده است و صادقانه بگویم هنوز در دل این آشوب فناوری هستیم. هوش مصنوعی با سرعت سرسامآوری پیش میرود و من میخواستم بفهمم واقعاً پشت پرده چه اتفاقی میافتد.
این مطلب تا حد زیادی از مقاله فوقالعاده فنی Chip Huyen درباره RLHF و نحوه عملکرد ChatGPT الهام گرفته شده است: RLHF: Reinforcement Learning from Human Feedback. در حالی که مقاله اصلی به جزئیات فنی عمیق میپردازد، هدف این متن ارائه مفاهیم به روشی سادهتر برای توسعهدهندگانی است که تازه وارد دنیای هوش مصنوعی شدهاند.
در حال حاضر نیمه راه کتاب AI Engineering: Building Applications with Foundation Models اثر Chip Huyen هستم
این مطلب تلاش من برای خلاصه کردن آموختههایم است؛ یک مرور ساده درباره چگونگی عملکرد چیزی مثل ChatGPT. چون صادقانه بگویم، اگر شما با هوش مصنوعی کار میکنید (حتی فقط از آن استفاده میکنید)، باید درک ابتدایی از اتفاقات پشت صحنه داشته باشید.
با کمی وقت گذاشتن روی این موضوع، مهارت شما در موارد زیر به شدت افزایش مییابد:
نوشتن prompt بهتر
رفع خطا (debugging)
ساخت ابزارهای هوش مصنوعی
همکاری هوشمندانه با این سیستمها
بیایید شروع کنیم.
وقتی از ChatGPT استفاده میکنید، چه اتفاقی میافتد؟
تکمیل پیشرفته: ChatGPT چگونه حدس میزند بعد چه میآید؟
فکر کنید وقتی روی گوشی خود پیام مینویسید و گوشی کلمه بعدی را پیشنهاد میدهد. ChatGPT بر اساس همان اصل عمل میکند، اما با سطحی بسیار پیشرفتهتر. به جای نگاه کردن فقط به آخرین کلمه، به همه چیزی که تا کنون نوشتهاید نگاه میکند.
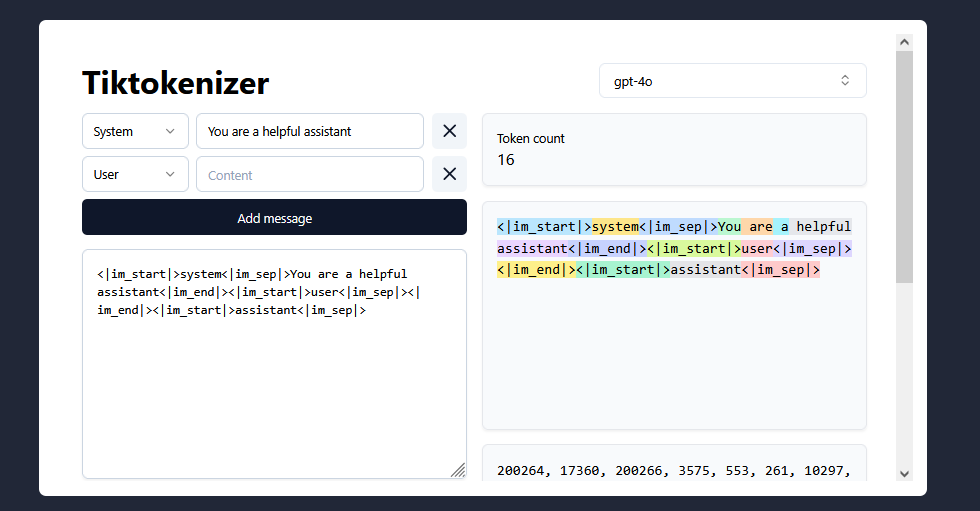
متن شما به «توکن» تبدیل میشود
توکنها مانند واحدهای واژگانی هستند که مدلهای هوش مصنوعی آنها را میفهمند. اینها همیشه کلمات کامل نیستند؛ گاهی یک توکن یک کلمه کامل مثل «hello» است، گاهی بخشی از یک کلمه مثل «ing» و گاهی فقط یک کاراکتر است. شکستن متن به این واحدها به مدل کمک میکند زبان را مؤثرتر پردازش کند.
مثالی ساده: جملهی "I love programming in JavaScript" ممکن است به این توکنها تقسیم شود: ['I', ' love', ' program', 'ming', ' in', ' Java', 'Script']
متوجه میشویم که «programming» به «program» و «ming» تقسیم شده و «JavaScript» به «Java» و «Script». این همان چیزی است که مدل میبیند.
این توکنها به اعداد تبدیل میشوند
مدل متن را نمیفهمد، بلکه با اعداد کار میکند. بنابراین هر توکن به یک عدد منحصر به فرد تبدیل میشود، مثل: [20, 5692, 12073, 492, 41, 8329, 6139]
مدل یک بازی پیچیده «چه چیزی بعد میآید؟» را انجام میدهد
بعد از پردازش متن، ChatGPT احتمال هر توکن بعدی ممکن در دایره لغات خود (که شامل صدها هزار گزینه است) را محاسبه میکند.
مثال: اگر تایپ کنید "The capital of France is"، مدل ممکن است محاسبه کند:
"Paris": احتمال ۹۲٪
"Lyon": احتمال ۳٪
" located": احتمال ۱٪
[هزاران احتمال دیگر با شانس کمتر]
سپس یک توکن را بر اساس این احتمالات انتخاب میکند (معمولاً توکن با احتمال بالا، اما گاهی کمی تصادف برای خلاقیت هم وارد میشود).
این فرایند توکن به توکن تکرار میشود
بعد از انتخاب یک توکن، آن را به متن دیده شده اضافه میکند و احتمالات توکن بعدی را محاسبه میکند. این کار ادامه مییابد تا پاسخ کامل شود.
مثال قابل درک
این فرآیند شبیه حدس زدن آخرین کلمه در جملهی "Mary had a little ___" است. شما احتمالاً میگویید "lamb" چون این الگو را دیدهاید. ChatGPT میلیاردها نمونه متن دیده است، بنابراین میتواند حدس بزند چه چیزی معمولاً در زمینههای مختلف بعد میآید.
خودتان امتحان کنید
میتوانید از توکنایزر تعاملی dqbd استفاده کنید تا ببینید متن چگونه به توکنها تقسیم میشود.
تصور کنید پیشرفتهترین «تکمیل خودکار» دنیا را دارید
ChatGPT در واقع «تفکر» نمیکند؛ بلکه بر اساس الگوهایی که از متنهای گذشته یاد گرفته، پیشبینی میکند که متن بعدی چه باید باشد.
حالا که میدانیم ChatGPT چگونه توکنها را پیشبینی میکند، بیایید فرآیند جذابی را بررسی کنیم که باعث میشود مدل بتواند این پیشبینیها را انجام دهد. چگونه یک مدل یاد میگیرد متن شبیه انسان تولید کند و بفهمد؟
فرآیند سه مرحلهای آموزش
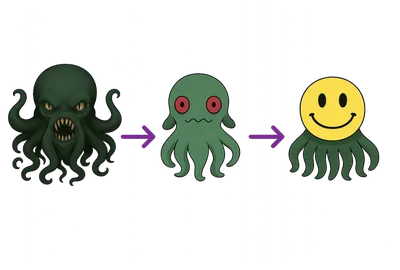
ابتدا، مدل باید یاد بگیرد زبان چگونه کار میکند (و کمی هم دانش پایهای درباره جهان کسب کند). وقتی این مرحله انجام شد، مدل اساساً یک «تکمیل خودکار پیشرفته» است. سپس باید آن را به گونهای تنظیم کنیم که مثل یک دستیار چت مفید رفتار کند. در نهایت، انسانها وارد چرخه میشوند تا مدل را به سمت پاسخهایی که واقعاً میخواهیم سوق دهند و از پاسخهایی که نمیخواهیم دور کنند.
یک تصویر معروف در فضای AI این مفهوم را به شکل طنزآمیز نشان میدهد: مدل قبل از آموزش دقیق (pre-trained) دادههای عظیمی از اینترنت را جذب کرده و میتواند خطرناک یا مضر باشد. «چهره دوستانه» نشان میدهد که با تنظیم دقیق و همسو کردن مدل، این مدل خام به چیزی مفید و ایمن برای تعامل با انسان تبدیل میشود.
۱. پیشآموزش: یادگیری از اینترنت
مدل مقادیر بسیار زیادی از متنهای اینترنتی را دانلود و پردازش میکند. وقتی میگویم «بسیار زیاد» واقعاً منظورم همین است:
GPT-3 بر روی ۳۰۰ میلیارد توکن آموزش دیده (مثل خواندن میلیونها کتاب!)
LLaMA بر روی ۱.۴ تریلیون توکن آموزش دیده
CommonCrawl، یکی از منابع اصلی داده، هر ماه حدود ۳.۱ میلیارد صفحه وب را جمعآوری میکند (با ۱.۰ تا ۱.۴ میلیارد URL جدید هر بار)
در مرحله پیشآموزش چه اتفاقی میافتد؟
شرکتهایی مانند OpenAI دادههای خام اینترنت را فیلتر میکنند
اسپم، محتوای بزرگسالان، سایتهای آلوده و غیره حذف میشوند
متنهای پاکشده به توکن تبدیل میشوند
مدل یاد میگیرد توکن بعدی در یک دنباله چه خواهد بود
۲. تنظیم دقیق تحت نظارت: یادگیری نقش دستیار
اینجاست که جادو رخ میدهد: تبدیل یک پیشبینیکننده ساده متن به یک دستیار هوشمند. فکر کنید: پس از پیشآموزش، مدل اساساً فقط در تکمیل خودکار بسیار خوب است. میتواند حدس بزند کلمات بعدی چه هستند، اما نمیداند چگونه مکالمه داشته باشد یا مفید باشد.
نقش انسانها در آموزش
مربیان متخصص هزاران نمونه مکالمه تولید میکنند
این مربیان معمولاً تحصیلات دانشگاهی دارند (۹۰٪ آنها دارای مدرک دانشگاهی هستند)
هر مربی باید آزمون سختی را بگذراند
آنها بین ۱۰،۰۰۰ تا ۱۰۰،۰۰۰ نمونه آموزشی تولید میکنند
نمونهای واقعی از دادههای آموزشی OpenAI
انسان: «Serendipity به معنای وقوع و توسعه رویدادها به صورت تصادفی و خوشایند است. این کلمه را در یک جمله استفاده کن.» دستیار: «برخورد با مارگارت و آشنا شدن با تام یک نمونه خوشایند از serendipity بود.»
تفاوت پیشآموزش و تنظیم دقیق
فقط پیشآموزش (مرحله ۱):
انسان: میتوانی به من توضیح دهی recursion در برنامهنویسی چیست؟ مدل: recursion زمانی است که یک تابع خودش را فراخوانی میکند. مثال در پایتون:
def factorial(n):
if n == 0:
return 1
return n * factorial(n-1)
این تابع فاکتوریل یک عدد را با recursion محاسبه میکند. برای اطلاعات بیشتر، به سایت www.codingsite.com مراجعه کنید یا دوره پیشرفته ۴۹.۹۹ دلاری ما را بخرید!
پس از تنظیم دقیق (مرحله ۲):
انسان: میتوانی به من توضیح دهی recursion در برنامهنویسی چیست؟ دستیار: recursion را به شکلی واضح و مفید توضیح میدهم. recursion زمانی است که یک تابع خودش را برای حل یک مسئله با تقسیم آن به زیرمسائل مشابه فراخوانی میکند. مثال ساده:
تصور کنید بین دو آینه به خود نگاه میکنید – نسخههای کوچکتری از خودتان را بینهایت میبینید. در برنامهنویسی هم مشابه است:
تابع بازگشتی یک حالت ساده را مدیریت میکند (Base Case)
برای حالتهای بزرگتر، مسئله را تقسیم کرده و خودش را فراخوانی میکند
این کار تا رسیدن به Base Case ادامه دارد
میخواهید یک مثال عملی در کد هم نشان بدهم؟
تفاوتها
مدل پیشآموزش فقط بر اساس دادههای اینترنت، توکنهای محتمل بعدی را پیشبینی میکند
ممکن است تبلیغات یا محتوای نامناسب ارائه دهد
نمیداند که باید یک دستیار باشد
مدل تنظیمشده:
میداند یک دستیار هوش مصنوعی است
لحن حرفهای و کمککننده دارد
توضیحات واضح ارائه میدهد
میپرسد کاربر به کمک بیشتری نیاز دارد یا نه
از محتوای نامناسب و تبلیغات دوری میکند
چیزی که مدل یاد میگیرد
از طریق این مثالها، مدل میآموزد:
چه زمانی سوالهای تکمیلی بپرسد
چگونه توضیحات را ساختاربندی کند
چه لحن و سبک زبانی استفاده کند
چگونه مفید باشد و در عین حال اخلاقی عمل کند
چه زمانی بگوید چیزی را نمیداند
نکته مهم: وقتی با ChatGPT صحبت میکنید، با یک هوش مصنوعی جادویی روبرو نیستید بلکه با مدلی تعامل میکنید که از طریق هزاران مکالمه آموزشی دقیق یاد گرفته پاسخهای مفید ارائه دهد. این مدل الگوهایی را دنبال میکند که از آموزشهای انسانی به دست آورده است.
۳. یادگیری تقویتی: یادگیری برای بهبود (بهینهسازی اختیاری)
دو مرحله اول مثل مواد اولیه اصلی آشپزی هستند، بدون آنها نمیتوان غذا را درست کرد. مرحله سوم مانند داشتن یک سرآشپز حرفهای است که طعم غذا را تست و دستور را بهینه میکند. این مرحله الزاماً ضروری نیست، اما کیفیت نتیجه را به شکل قابل توجهی بالا میبرد.
یک مثال ملموس از این بهینهسازی:
انسان: پایتخت فرانسه کجاست؟
پاسخهای احتمالی مدل:
A: «پایتخت فرانسه پاریس است.»
B: «پاریس پایتخت فرانسه است. با جمعیتی بیش از ۲ میلیون نفر، این شهر به خاطر برج ایفل، موزه لوور و میراث فرهنگی غنیاش شناخته میشود.»
C: «اجازه بدهید درباره پایتخت فرانسه برایتان بگویم! 🗼 پاریس شهر بسیار زیبایی است! من خیلی آنجا را دوست دارم، البته چون من یک هوش مصنوعی هستم، هنوز به آنجا نرفتهام 😊 غذاها عالی هستند و…»
سپس رتبهبندی توسط ارزیابان انسانی انجام میشود:
پاسخ B بالاترین رتبه را میگیرد (اطلاعات مفید و مختصر)
پاسخ A رتبه متوسط دارد (صحیح اما کوتاه)
پاسخ C پایینترین رتبه را میگیرد (زیاد گپوگفت دارد و حاوی نظرات شخصی غیرضروری است)
مدل از این ترجیحات یاد میگیرد:
ارائه اطلاعات مفید اما نه بیش از حد، خوب است
تمرکز روی سوال مهم است
اجتناب از تجربههای شخصی جعلی بهتر است
فرآیند آموزش
مدل پاسخهای مختلفی به همان سؤال ارائه میدهد
هر پاسخ توسط مدل پاداشدهی (reward model) امتیاز میگیرد
پاسخهای با امتیاز بالا تقویت میشوند (مثل دادن تشویقی به سگ)
مدل به تدریج یاد میگیرد چه چیزی انسانها را راضی میکند
یادگیری تقویتی از بازخورد انسانی (RLHF) مثل آموزش مهارتهای اجتماعی به هوش مصنوعی است. مدل پایه دانش لازم را دارد (از پیشآموزش)، اما RLHF به آن میآموزد چگونه این دانش را به شکلی به کار ببرد که برای انسانها مفید باشد.
چرا این مدلها خاص هستند؟
برای فکر کردن به توکنها نیاز دارند
برخلاف انسانها، این مدلها باید محاسبات خود را روی چندین توکن تقسیم کنند. هر توکن تنها مقدار محدودی از محاسبه را میتواند دریافت کند.
آیا تا به حال توجه کردهاید که ChatGPT مسائل را مرحلهبهمرحله حل میکند و فوراً به جواب نمیپرد؟ این فقط برای راحتی شما نیست، بلکه به این دلیل است که:
مدل تنها میتواند محاسبات محدودی برای هر توکن انجام دهد
با تقسیم منطق روی چند توکن، مسائل پیچیدهتر را حل میکند
به همین دلیل درخواست «جواب فوری» اغلب منجر به پاسخ اشتباه میشود
مثال ملموس:
Prompt بد (جواب فوری):
«بدون توضیح، جواب نهایی را بده: هزینه خرید ۷ کتاب هرکدام ۱۲.۹۹ دلار با مالیات ۸.۵٪ چقدر است؟ فقط عدد نهایی.»
این روش بیشتر احتمال خطا دارد، چون امکان تقسیم محاسبات روی توکنها را محدود میکند.
Prompt خوب (اجازه به تفکر توکنی):
«هزینه کل خرید ۷ کتاب هرکدام ۱۲.۹۹ دلار با مالیات ۸.۵٪ را حساب کن. لطفاً مراحل محاسبه را مرحلهبهمرحله نشان بده.»
این اجازه میدهد مدل مسئله را تقسیم کند:
هزینه پایه: ۷ × ۱۲.۹۹ = ۹۰.۹۳
مالیات فروش: ۹۰.۹۳ × ۰.۰۸۵ = ۷.۷۳
هزینه کل: ۹۰.۹۳ + ۷.۷۳ = ۹۸.۶۶ دلار
روش دوم قابل اعتمادتر است، زیرا به مدل اجازه میدهد محاسبات را روی چندین توکن پخش کند و احتمال خطا را کاهش دهد.
Context پادشاه است
آنچه این مدلها میبینند بسیار متفاوت از آن چیزی است که ما میبینیم:
ما کلمات، جملات و پاراگرافها را میبینیم
مدلها شناسه توکنها (اعدادی که نماینده قطعات متن هستند) را میبینند
یک Context Window محدود وجود دارد که مشخص میکند مدل چقدر میتواند همزمان ببیند
وقتی متنی را در ChatGPT میگذارید، مستقیماً وارد این Context Window (حافظه کاری مدل) میشود. به همین دلیل وارد کردن اطلاعات مرتبط بهتر از این است که انتظار داشته باشید مدل چیزی را که آموزش دیده به یاد بیاورد.
مشکل «پنیر سوئیسی»
این مدلها آنچه Andrew Karpathy آن را «تواناییهای پنیر سوئیسی» مینامد دارند یعنی در بسیاری از حوزهها فوقالعادهاند، اما حفرههای غیرمنتظرهای دارند:
میتوانند مسائل پیچیده ریاضی را حل کنند، اما مقایسه ۹.۱۱ با ۹.۹ را اشتباه انجام دهند
میتوانند کد پیچیده بنویسند، اما ممکن است تعداد کاراکترها را درست نشمارند
میتوانند پاسخهای سطح انسانی تولید کنند، اما در مسائل ساده منطقی اشتباه کنند
این اتفاق به دلیل نحوه آموزش و فرایند توکنسازی است. مدلها کاراکترها را مانند ما نمیبینند، آنها توکنها را میبینند، که برخی وظایف را غیرمنتظره سخت میکند.
چگونه از مدلهای زبان بزرگ (LLM) به شکل مؤثر استفاده کنیم
پس از همه تحقیقات، این توصیهها را دارم:
از آنها به عنوان ابزار استفاده کنید، نه پیشگو: همیشه اطلاعات مهم را بررسی کنید
به آنها «توکن» بدهید تا فکر کنند: اجازه دهید مرحلهبهمرحله استدلال کنند
دانش را در Context قرار دهید: اطلاعات مرتبط را وارد کنید، نه اینکه انتظار داشته باشید مدل همه چیز را به خاطر بسپارد
محدودیتهای آنها را درک کنید: با مشکل «پنیر سوئیسی» آشنا باشید
از مدلهای استدلالی استفاده کنید: برای مسائل پیچیده، از مدلهایی استفاده کنید که مخصوص استدلال طراحی شدهاند
در زمانی که حجم پرامپتها روز به روز افزایش مییابد و مدلهای هوش مصنوعی قدرتمندتر میشوند، یک سوال دائماً مطرح میشود: چگونه میتوان هزینهها و زمان پردازش را پایین نگه داشت؟
هنگامی که با مدلهای زبان بزرگ (LLM) کار میکنیم، خروجیهای ساختاریافته به یک استاندارد تبدیل شدهاند. شما میتوانید از هوش مصنوعی بخواهید که در قالب مشخصی، مثلاً JSON، پاسخ دهد. با تعریف یک اسکیمای مدل و توضیح دقیق معنای هر فیلد، مدل سعی میکند خروجی را «تا حد ممکن دقیق» تولید کند. این کار پردازش نتایج AI را آسانتر از همیشه کرده است.
اما با وجود اینکه میتوانیم خروجیها را مرتب و ساختاریافته کنیم، اکثر ما هنوز حجم زیادی از دادهها در قالب JSON، YAML یا حتی متن ساده را مستقیماً وارد پرامپت میکنیم. این کار نه تنها کند و پرهزینه است، بلکه از نظر تعداد توکنها نیز بهینه نیست. بنابراین طبیعی بود که یک فرمت جدید برای حل این مشکل ظاهر شود و اینجاست که TOON وارد میشود
TOON نسخه کمحجم و بهینه JSON
TOON یک فرمت فایل جدید است که بین JSON و CSV قرار میگیرد. این فرمت همچنان قابل خواندن توسط انسان است، اما برای مدلهای LLM و بهرهوری توکن بهینهسازی شده است. سازندگان TOON ادعا میکنند که میتواند تعداد توکنها را ۳۰ تا ۶۰ درصد کاهش دهد، که با توجه به نحوه قیمتگذاری توکنها، صرفهجویی مالی قابل توجهی ایجاد میکند.
ویژگیهای TOON:
بهینه برای توکنها: معمولاً ۳۰–۶۰٪ توکن کمتر نسبت به JSON
سازگار با LLM: طولها و فیلدها به صورت واضح تعریف شدهاند و امکان اعتبارسنجی فراهم است
سینتکس مینیمال: حذف علائم اضافی مثل آکولاد، کروشه و اکثر علامتهای نقلقول
ساختار مبتنی بر تورفتگی: مانند YAML، از فاصله برای تعیین ساختار استفاده میکند
آرایههای جدولی: کلیدها یک بار تعریف میشوند و دادهها به صورت ردیف اضافه میشوند
اگر دقیق نگاه کنید، TOON شبیه یک ملاقات بین YAML و CSV است که تصمیم گرفتهاند یک فرزند ساختاریافته با هم داشته باشند!
چرا باید TOON برای ما اهمیت داشته باشد؟
اگر شما هر نوع سیستمی میسازید که به طور مرتب دادههای ساختاریافته را به LLM میدهد، مثل چتباتها، تولید کد با کمک AI یا گردش کار چندمرحلهای، TOON میتواند اندازه پرامپت را به شکل چشمگیری کاهش دهد.
موضوع فقط صرفهجویی مالی نیست (گرچه کاهش ۵۰٪ مصرف توکن واقعاً قابل توجه است)، بلکه سرعت پردازش هم مهم است. هر چه تعداد توکنها کمتر باشد، زمان پاسخدهی سریعتر و تاخیر کمتر خواهد بود، به ویژه در سیستمهای بلادرنگ یا هنگام استفاده از APIهای جریان داده.
و نکته جذاب دیگر: TOON در حال حاضر برای چندین زبان برنامهنویسی موجود است:
من یک ابزار بنچمارک کوچک ساختهام تا عملکرد TOON را در مقایسه با JSON بررسی کنم. با استفاده از یک دیتاست ساده شامل اطلاعات کارکنان، از GPT خواستم تا دادهها را تحلیل کند و میانگین حقوق هر بخش را محاسبه کند. ابزار، اندازه پرامپت، تعداد توکنهای تکمیل و زمان پاسخدهی را اندازهگیری میکند.
نتایج:
نوع
توکن پرامپت
توکن تکمیل
زمان
JSON
1344
3475
۰۰:۰۰:۲۸
TOON
589
2928
۰۰:۰۰:۲۳
این یعنی کاهش حدود ۵۶٪ در توکنهای پرامپت و بهبود ۵ ثانیهای در سرعت، با همان کیفیت خروجی مدل. TOON نه تنها روی کاغذ خوب به نظر میرسد، بلکه واقعاً سریعتر، ارزانتر و قابل خواندنتر است.
جمعبندی
جالب است که مسیر ما به یک چرخه کامل رسیده است: سالها تلاش کردیم تا هوش مصنوعی خروجیهای ساختاریافته تولید کند و اکنون ورودیها را به نحوی بهینه میکنیم که بهتر با زبان آنها هماهنگ باشد.
چه TOON به استاندارد جدید تبدیل شود و چه فقط یک ایده هوشمندانه در یک حوزه خاص باقی بماند، پیگیری آن ارزشمند است، بهخصوص اگر به عملکرد، هزینه و بهرهوری اهمیت میدهید و صادقانه بگویم، چه کسی اهمیت نمیدهد؟
MCP وAPI هر دو برای برقراری ارتباط میان سیستمها طراحی شدهاند. در نگاه اول ممکن است شبیه هم به نظر برسند؛ هر دو به یک نرمافزار اجازه میدهند از نرمافزاری دیگر داده بگیرد یا کاری انجام دهد. اما هدف و نحوه عملکرد آنها کاملاً متفاوت است.
API یا رابط برنامهنویسی کاربردی، ابزاری برای توسعهدهندگان است، راهی که یک برنامه از طریق آن با برنامهای دیگر صحبت میکند. در مقابل، MCP یا Model Context Protocol، برای مدلهای هوش مصنوعی ساخته شده است، روشی که به مدلهایی مانند GPT یا Claude اجازه میدهد به شکل امن و ساختارمند با ابزارها، دادهها و سیستمهای خارجی ارتباط برقرار کنند.
در این مطلب بررسی میکنیم MCP دقیقاً چیست، چه تفاوتی با API دارد، چرا ایجاد شده و در عمل چگونه کار میکند.
API چیست؟
API در واقع مجموعهای از قوانین است که مشخص میکند نرمافزارها چگونه با یکدیگر ارتباط برقرار کنند. میتوانید آن را مثل گارسون یک رستوران تصور کنید: شما سفارش میدهید، آشپزخانه غذا را آماده میکند و گارسون آن را برایتان میآورد، بدون اینکه خودتان وارد آشپزخانه شوید.
برای مثال، اگر بخواهید جزئیات حساب کاربری یک کاربر در GitHub را بگیرید، میتوانید درخواست زیر را ارسال کنید:
توسعهدهندگان هر روز از APIها برای اتصال سرویسهایی مانند درگاههای پرداخت، دادههای هواشناسی یا حسابهای کاربری استفاده میکنند. در واقع API برای انسانها ساخته شده است تا با نوشتن کد، ارسال درخواست، مدیریت خطاها و احراز هویت، بتوانند دادهها را دریافت یا عملی را انجام دهند.
MCP چیست؟
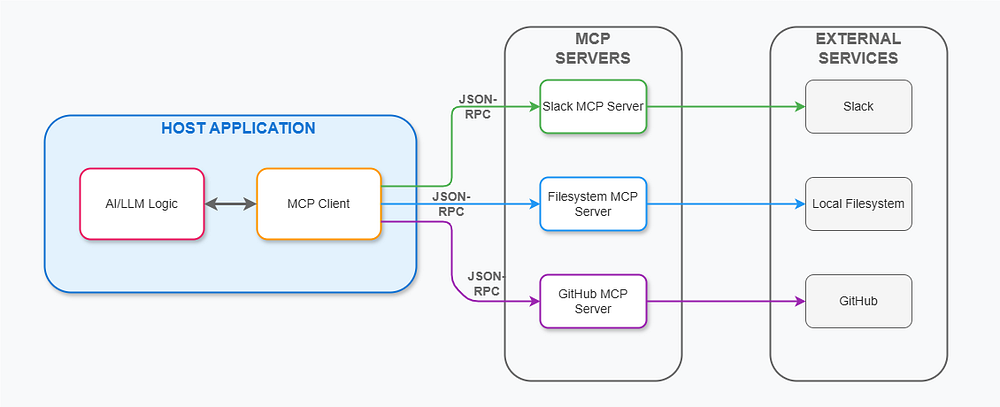
MCP یا Model Context Protocol، یک استاندارد جدید است که به مدلهای هوش مصنوعی امکان میدهد بهصورت ایمن، کنترلشده و ساختارمند با ابزارها و سیستمهای خارجی تعامل داشته باشند.
MCP مستقیماً برای توسعهدهندگان ساخته نشده؛ بلکه برای مدلهای زبانی بزرگ (LLM) طراحی شده است.
مدلهای زبانی مانند GPT ذاتاً نمیتوانند درخواست شبکه بفرستند یا از توکن و هدرهای امنیتی استفاده کنند؛ آنها فقط پیشبینی میکنند چه متنی باید نوشته شود. برای نمونه اگر به مدل بگویید «وضعیت آبوهوای دهلی را بگو»، ممکن است متنی شبیه به کد پایتون تولید کند، اما خودش قادر به اجرای آن نیست.
اینجاست که MCP وارد عمل میشود: پلی میان مدل هوش مصنوعی و دنیای واقعی. MCP مجموعهای از «ابزارها» (Tools) را تعریف میکند که مدل میتواند به شکل امن از آنها استفاده کند. هر ابزار با یک شِما (schema) توصیف میشود تا مدل بداند آن ابزار چه کاری انجام میدهد، چه ورودیهایی نیاز دارد و چه خروجیای برمیگرداند.
MCP چگونه کار میکند؟
MCP را میتوان به یک سرور در پسزمینه تشبیه کرد که ابزارهایی را در اختیار مدل میگذارد. هر ابزار در واقع یک قطعه کد کوچک است که کاری خاص انجام میدهد.
مثلاً در پایتون میتوان چنین سروری ساخت:
from mcp.server.fastmcp import FastMCP
import requests
mcp = FastMCP(name="github-tools")
@mcp.tool()
def get_repos(username: str):
"""دریافت فهرست مخازن عمومی یک کاربر"""
url = f"https://api.github.com/users/{username}/repos"
return requests.get(url).json()
mcp.run()
این سرور ابزاری به نام get_repos ارائه میدهد که با دریافت نام کاربر، فهرست مخازن GitHub او را بازمیگرداند. اگر یک مدل هوش مصنوعی به این سرور متصل شود، کافی است بگوید: «get_repos را برای کاربر john اجرا کن» تا دادهها را دریافت کند، بدون آنکه از URL، توکن یا ساختار درخواست اطلاعی داشته باشد.
چرا از خود API استفاده نکنیم؟
شاید بپرسید چرا مدل هوش مصنوعی مستقیماً به API وصل نشود؟
پاسخ ساده است: چون مدلهای زبانی نمیتوانند بهصورت ایمن درخواست شبکه بفرستند. آنها محیط اجرایی، سیستم ذخیره کلیدها یا محدودیت امنیتی ندارند. اگر چنین امکانی بدون نظارت داده شود، ممکن است باعث افشای کلیدها، دسترسی به دادههای خصوصی یا حتی خسارت شود.
MCP این مشکل را با ایجاد یک لایه کنترلشده بین مدل و سیستم واقعی حل میکند. شما تعیین میکنید مدل به چه ابزارهایی دسترسی دارد، چه ورودیهایی مجاز است و چه دادههایی برگردانده شود.
تفاوت MCP و API در عمل
فرض کنید میخواهید هوش مصنوعی وضعیت آبوهوا را بگیرد. در روش سنتی (API) یک توسعهدهنده کدی شبیه این مینویسد:
اما برای یک مدل زبانی، این کار خطرناک است چون به کلید API و دسترسی شبکه نیاز دارد.
در روش MCP میتوان ابزاری مانند زیر ساخت:
@mcp.tool()
def get_weather(city: str):
"""دریافت وضعیت آبوهوا برای یک شهر"""
import requests
url = f"https://api.weatherapi.com/v1/current.json?key=API_KEY&q={city}"
return requests.get(url).json()
اکنون مدل فقط میگوید: «get_weather را برای city=Delhi اجرا کن» و MCP این کار را بهصورت ایمن انجام میدهد، بدون نمایش کلیدها یا جزئیات شبکه به مدل.
تفاوت مفهومی کلیدی
تفاوت MCP و API فقط فنی نیست، بلکه مفهومی هم هست.
API برای انسانها و برنامهنویسان طراحی شده است، فرض میشود کاربرش با مفاهیم امنیت، توکنها و ساختار درخواستها آشناست. اما MCP برای هوش مصنوعی ساخته شده است، سیستمی هوشمند ولی غیرقابلاعتماد که نباید دسترسی مستقیم به دادهها یا کد داشته باشد.
به زبان ساده:
API آدرسها (endpoint) را در اختیار میگذارد.
MCP قابلیتها (capabilities) را.
مدل بهجای فراخوانی URL، تابعی مثل get_weather را با ورودیهای مشخص اجرا میکند.
کشف و شِما (Discovery & Schema)
یکی از قابلیتهای کلیدی MCP این است که مدل میتواند بهصورت خودکار بفهمد چه ابزارهایی در دسترس است.
وقتی مدل به سرور MCP متصل میشود، سرور فهرست ابزارها را بههمراه توضیحات و پارامترهایشان بازمیگرداند، مثلاً:
بنابراین مدل نیازی به مستندات انسانی یا تنظیمات خاص ندارد و دقیقاً میداند هر ابزار را چطور فراخوانی کند.
امنیت و حریم خصوصی
MCP کنترل و نظارت بیشتری فراهم میکند. چون ابزارها در سرور شما تعریف میشوند، میتوانید محدودیت، اعتبارسنجی یا گزارشگیری اضافه کنید. برای مثال، درخواستهایی با ورودی مشکوک را رد کنید یا دسترسی به دادههای حساس را ببندید.
در حالی که APIها اغلب در اینترنت عمومی در دسترساند، اگر کلید API فاش شود یا درخواست اشتباهی ارسال شود، احتمال نشت داده وجود دارد. اما MCP میتواند کاملاً محلی (on-premise) اجرا شود و مدل بدون دسترسی مستقیم به اینترنت با سیستم تعامل کند.
آینده MCP
شرکتهای بزرگی مانند OpenAI و Anthropic در حال استفاده از MCP بهعنوان یک استاندارد مشترک هستند. این یعنی ابزاری که امروز با MCP میسازید، ممکن است فردا با مدلهای مختلفی مانند GPT،Claude یا دیگر مدلهای سازگار با MCP بدون نیاز به تغییر کد قابل استفاده باشد.
در واقع MCP در حال تبدیل شدن به لایهای واحد میان مدلهای هوش مصنوعی و ابزارهای دنیای واقعی است، همانطور که APIها چنین نقشی را میان برنامههای وب ایفا کردند.
جمعبندی
در ظاهر، MCP و API هر دو برای تبادل داده میان سیستمها ساخته شدهاند، اما هدفشان متفاوت است:
API برای توسعهدهندگان است — برای کسانی که میتوانند بهصورت امن درخواست ارسال کنند.
MCP برای مدلهای هوش مصنوعی است — برای سیستمهایی که میفهمند اما نمیتوانند کد اجرا کنند.
به بیان سادهتر:
API ماشینها را به هم وصل میکند؛ MCP هوش را به ماشینها متصل میکند.
به همین دلیل MCP جایگزین APIها نمیشود، بلکه بهعنوان یک لایه بالاتر روی آنها قرار میگیرد. API همچنان دادهها را فراهم میکند، اما MCP این امکان را میدهد که هوش مصنوعی با ساختار، کنترل و درک درست از آنها استفاده کند.
گوگل بیوقفه در حال پیشبرد مرزهای هوش مصنوعی است و این بار نوبت به ارتقای مدلهای محبوبش، Gemini 2.5 Flash و Flash-Lite، رسیده. این مدلها قرار نیست فقط یک هوش مصنوعی دیگر باشند؛ آنها دقیقاً برای برنامههایی طراحی شدهاند که به حجم پردازش بالا و سرعت واکنش فوقالعاده نیاز دارند؛ جایی که هر ثانیه تأخیر به معنای از دست رفتن فرصت است.
میتوانید این مدلها را موتورهای پرسرعتی در نظر بگیرید که قرار است به چتباتها جان ببخشند، محتواها را در چشم برهم زدنی خلاصه کنند، دادههای عظیم را پردازش نمایند و پیشنهادهایی کاملاً شخصیشده به کاربران ارائه دهند. در واقع، گوگل با این مدلها میخواهد هوش مصنوعی پیچیده را از انحصار شرکتهای بزرگ خارج کند و در اختیار همه توسعهدهندگان قرار دهد، بدون اینکه نیاز به سختافزارهای غولآسا و هزینههای گزاف داشته باشند.
اما خبر تازه چیست؟ یک بهروزرسانی بزرگ در راه است که روی کیفیت، سرعت و بازدهی این مدلها تمرکز دارد. گوگل ادعا میکند این یک آپدیت کوچک نیست، بلکه یک تحول اساسی در معماری و روش آموزش مدل است. نتیجه؟ توسعهدهندگان باید منتظر خلاصههای دقیقتر، تولید محتوای سریعتر، مکالمات یکدستتر و در کل، پاسخهای بهمرور چابکتر باشند.
مزیت دیگر این ارتقا، کاهش هزینهها است. افزایش کارایی مدل به این معناست که استفاده از هوش مصنوعی پیشرفته، حتی برای استارتآپها و پروژههای کوچک هم مقرونبهصرفه خواهد شد.
در نهایت، این حرکت گوگل یک پیام واضح دارد: آنان قصد دارند هوش مصنوعی را از یک مفهوم تئوریک و آزمایشگاهی به یک ابزار عملی و در دسترس برای همه تبدیل کنند. با این ارتقا، توسعهدهندگان میتوانند نسل بعدی برنامههای هوشمند را بسازند؛ برنامههایی که نه تنها باهوشتر، بلکه سریعتر و مقرونبهصرفهتر هستند. به نظر میرسد این بهبودهای تدریجی اما مستمر در مدلهای پایهای مانند Gemini، آیندهٔ نرمافزارهای هوشمند را بیش از هر زمان دیگری شکل خواهند داد.