اوبر بهتازگی جزئیات سیستمی داخلی با نام Ceilometer را منتشر کرده است؛ یک چارچوب بنچمارک تطبیقی که برای ارزیابی عملکرد زیرساخت اوبر فراتر از شاخصهای سطح اپلیکیشن طراحی شده است. این سیستم به اوبر کمک میکند تا SKUهای جدید ابری را ارزیابی کند، تغییرات زیرساختی را اعتبارسنجی کند و ابتکارات بهینهسازی و افزایش بهرهوری را با استفاده از بنچمارکهایی تکرارپذیر و نزدیک به شرایط واقعی تولید (Production-like) اندازهگیری کند.
با افزایش تنوع سختافزارها و ارائهدهندگان ابری، زیرساخت اوبر به ابزاری نیاز داشت که بتواند سیگنالهای عملکردی یکسان، قابلاعتماد و مبتنی بر داده را در محیطهای مختلف ارائه دهد. Ceilometer پاسخی به همین نیاز است.
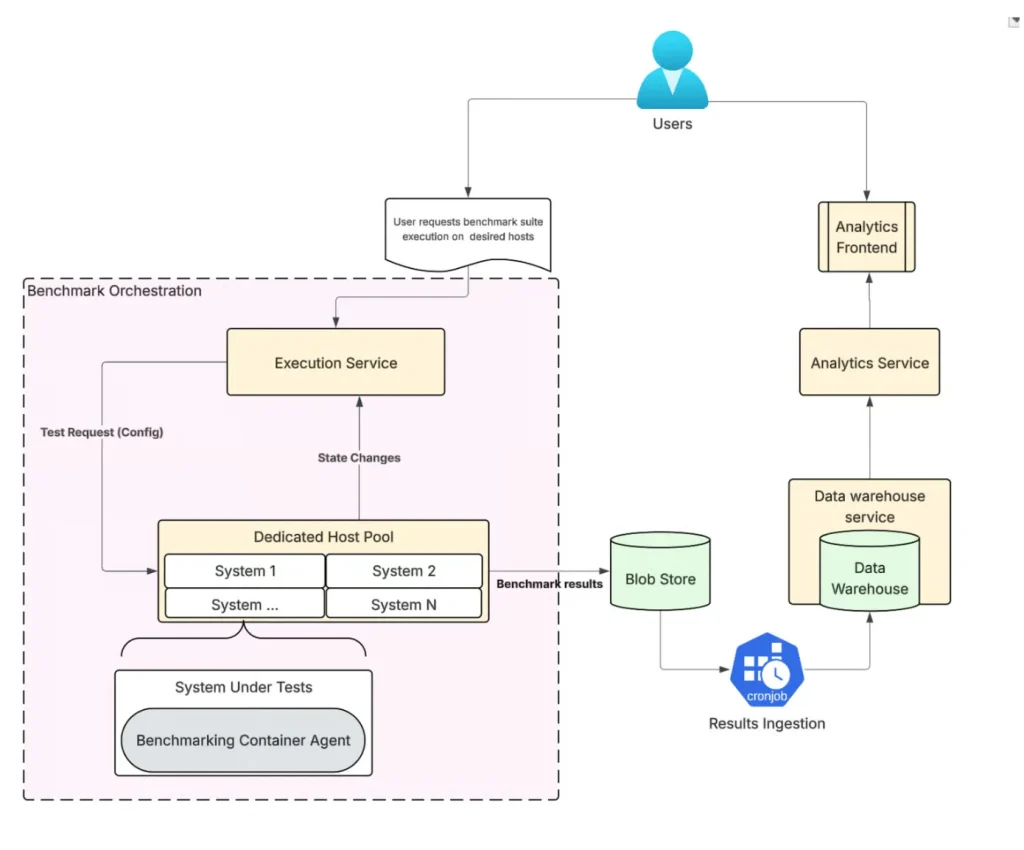
نمودار معماری سقفسنج (منبع: پست وبلاگ اوبر)
پایان بنچمارکهای دستی و پراکنده
در مقیاس اوبر، بنچمارکگیری از زیرساختها در گذشته فرآیندی پراکنده، دستی و غیرقابلتکرار بود. مهندسان معمولاً از اسکریپتهای موردی، اجرای تستهای جداگانه و حتی فایلهای اکسل برای مقایسه نتایج استفاده میکردند؛ روشی که بازتولید نتایج یا مقایسه عملکرد بین تیمها را بسیار دشوار میساخت.
Ceilometer این رویکرد سنتی را کنار گذاشته و یک پلتفرم متمرکز ارائه میدهد که کل چرخه بنچمارک (از زمانبندی و اجرا گرفته تا جمعآوری و تحلیل نتایج) را بهصورت خودکار انجام میدهد. این کار امکان مقایسه استاندارد و منسجم میان سرورها، بارهای کاری و محیطهای مختلف را فراهم میکند.
معماری توزیعشده برای نتایج قابلاعتماد
Ceilometer بهصورت یک سیستم توزیعشده طراحی شده که اجرای بنچمارکها را روی ماشینهای اختصاصی هماهنگ میکند. تستها بهصورت موازی اجرا میشوند تا رفتار بارهای کاری واقعی را شبیهسازی کنند. خروجی خام تستها در فضای ذخیرهسازی پایدار (Blob Storage) نگهداری شده و پس از اعتبارسنجی و نرمالسازی، وارد انبار داده متمرکز اوبر میشوند.
این نتایج در کنار متریکهای تولیدی (Production Metrics) قابل پرسوجو و تحلیل هستند. به گفته مهندسان اوبر، این معماری به آنها اجازه داده است تا افت عملکرد، ناکارآمدیهای پیکربندی یا تفاوتهای سطح سختافزار را با استفاده از یک مدل داده یکپارچه شناسایی کنند.
پشتیبانی از طیف گستردهای از بارهای کاری
Ceilometer از انواع مختلف بارهای کاری پشتیبانی میکند:
- بنچمارکهای مصنوعی (Synthetic) مانند
SpecCPU2017، SPECjbb2015، NetPerf و FIO برای سنجش عملکرد CPU، حافظه، شبکه و ذخیرهسازی - برای سیستمهای Stateful، این چارچوب با پلتفرم Odin اوبر یکپارچه شده تا بارهای کاری دیتابیس را در شرایطی نزدیک به تولید ارزیابی کند
- سرویسهای Stateless نیز با استفاده از فریمورک Ballast تست میشوند؛ سیستمی که ترافیک تولید را بهصورت تطبیقی شبیهسازی میکند
از ارزیابی سرورها تا اعتبارسنجی تغییرات زیرساخت
یکی از کاربردهای اصلی Ceilometer، ارزیابی شکل سرورها (Server Shape) و تأیید SKUهای ابری جدید است. تولیدکنندگان سختافزار و ارائهدهندگان سرویس ابری میتوانند این بنچمارکها را در محیط خود اجرا کرده و نتایج را با اوبر به اشتراک بگذارند؛ موضوعی که به اوبر امکان میدهد پیش از ورود یک SKU جدید، دید دقیقی از عملکرد آن داشته باشد.
کاربرد مهم دیگر، اعتبارسنجی تغییرات زیرساختی است. با استفاده از بنچمارکهای هدفمند، اوبر میتواند افت عملکرد ناشی از بهروزرسانی نرمافزار، تغییرات کرنل، فریمور، یا تنظیمات سیستمی را بهصورت دقیق شناسایی کند. نتایج Ceilometer در طول زمان، میان محیطهای مختلف و بارهای کاری گوناگون قابل مقایسه هستند و تصویری عمیقتر از تأثیر تغییرات زیرساخت (فراتر از متریکهای سطح اپلیکیشن) ارائه میدهند.
نگاه اوبر به آینده Ceilometer
Nav Kankani، مدیر ارشد مهندسی و معمار پلتفرم در تیم زیرساخت اوبر، در پستی در لینکدین میگوید:
«چارچوب بنچمارک تطبیقی اوبر، بارهای کاری واقعی تولید را مدلسازی میکند تا تصمیمگیری درباره پلتفرمهای ابری را هدایت کند. Ceilometer با پوشش بارهای Stateless، Stateful، Batch و AI/ML امکان بررسی همطراحی سختافزار و نرمافزار را ساده کرده و به افزایش بهرهوری در کل ناوگان زیرساختی ما کمک میکند.»
با ادامه تحول زیرساختهای اوبر، Ceilometer نیز در حال گسترش است. از جمله برنامههای آینده میتوان به موارد زیر اشاره کرد:
- استفاده از هوش مصنوعی و یادگیری ماشین برای پیشبینی افت عملکرد و شناسایی ریشه مشکلات
- پشتیبانی گستردهتر از فناوریها و الگوهای نوظهور زیرساختی
- تشخیص ناهنجاری پیشرفته برای شناسایی سریع انحرافهای غیرمنتظره عملکرد
- ارائه متریکهای دقیق در سطح اجزا برای CPU، حافظه، ذخیرهسازی و شبکه
همچنین مهندسان اوبر قصد دارند از Ceilometer برای تستهای اعتبارسنجی پیوسته بهصورت Canary استفاده کنند؛ بهطوری که بنچمارکها بهصورت خودکار و دورهای اجرا شوند و در صورت عبور از آستانههای عملکردی، تیمها بهسرعت مطلع شوند. رویکردی که تصمیمگیریهای زیرساختی را سریعتر، دقیقتر و قابلاعتمادتر میکند.